
Currently, I am curating the German version of the Real Scientist twitter account and this is a lot of fun. At Real Scientist real scientists get to tweet about their work and benefit from the following of the account, which is usually larger than their own. During the week I have used twitter’s survey function to find out more about the follower’s sleep habits, me being a sleep and memory researcher and all. This was helpful to break down some of the more complicated information I wanted to relay. Here is how I tried to use twitter to also collect some memory data. Here is a link to the associated twitter thread.
After one of the sleep surveys, I got into a little bit of a discussion with one of the followers about how to analyse these data and of course the restrictions of twitter surveys don’t really allow a lot of flexibility. This prompted me to use an outside survey service for my little experiment. Essentially I wanted to use the Deese–Roediger–McDermott paradigm (Deese 1959, Roediger & McDermott 1995) to demonstrate to the followers how easy it is to induce false memories.

List of German words that can be grouped by the category words “süß”, “Mann”, “Spinne” and “schwarz”. Note that the category words were not used in the lists and participants were not told that there were categories.
To this end I showed a list of German (this was German Real Scientist after all) words that pertained to four categories and were randomly mixed. I asked the twitter followers to memorize the words and told them I would delete the tweet in the evening. The next day, I provided a survey using a third party service, which contained old words (from the list), new words and lure words. It asked participants for each word, if it was part of the originally learned list. New words were not related to the learned list in any meaningful way, but lure words were associated to the four categories of the original list. In the end, 22 followers (of 3000) actually filled in the survey.
Luckily for me, the data showed exactly what could be expected from the literature (I used simple two-sided paired t-tests for the p-values). 1. Trivially, hits (correctly identifying an old word as being part of the learned list) were more frequent than false alarms for new words (incorrectly identifying a new word as being part of the learned list). 2. Importantly, false alarms for lures (incorrectly identifying a lure as being part of the learned list) were more frequent than false alarms for new words. 3. Reassuringly, hits were still more frequent than false alarms for lures. These data nicely demonstrated that our brain’s memory system does not work like a hard drive and retrieval is a reconstructive process prone to error.
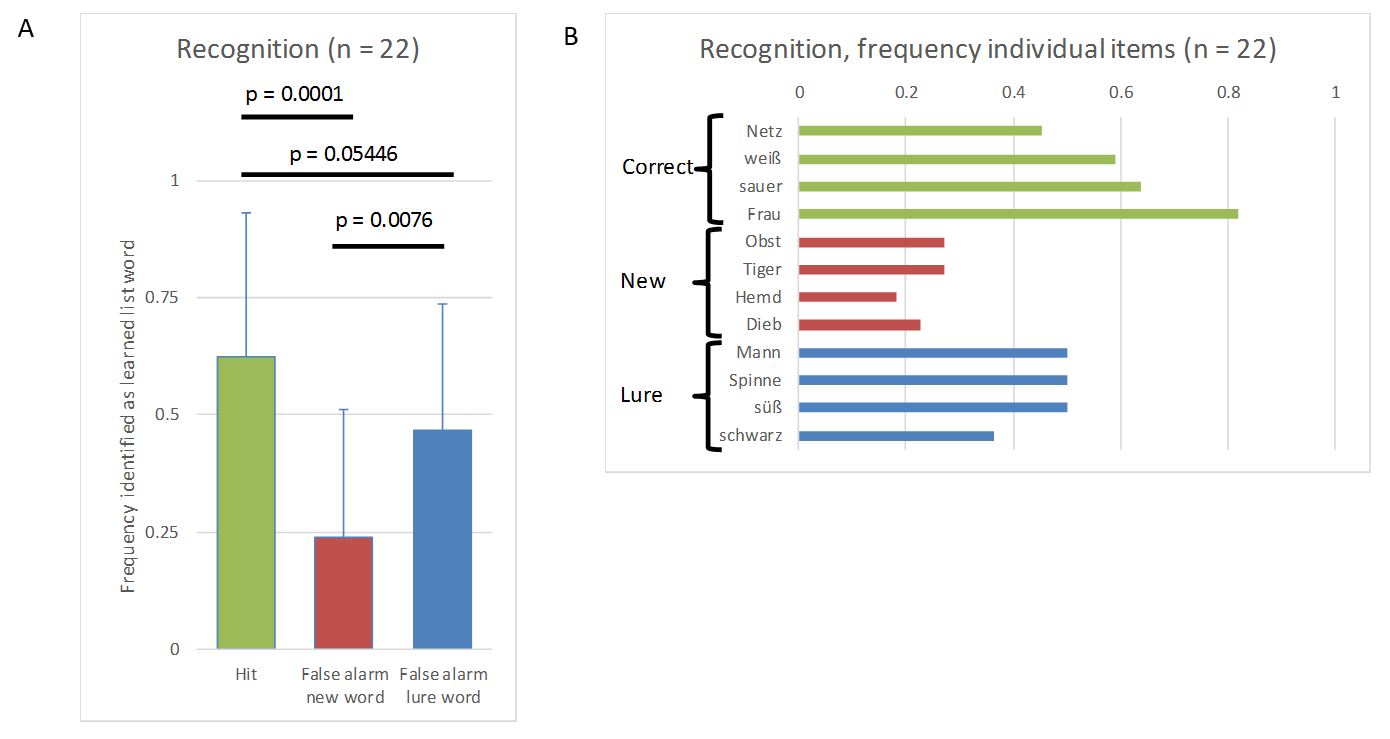
Data from the experiment. A) Relative frequency (mean and standard deviation) of hits and false alarms for new words and lures. B) Absolute frequency for each item being identified as an item from the learning list by the 22 participants.
All in all, I must say that I am quite happy that this little demonstration worked out and it nicely showed that you can collect more complex data via twitter. However, I was a bit shocked that I only got 22 respondents to the survey. When running a survey internally on twitter, I received about 200-300 respondents using this account. The third party service was optimized for mobile devices, so I don’t think that was an issue. It would have been so cool to run such an experiment on a couple of hundreds of people just by posting it on twitter. However, it seems leaving twitter is a much higher hurdle than I had anticipated.

